Article
Real-time personalization isn't an agent-per-user problem
Best for medium to large e-commerce stores.
This past week I've been trying to nail down exactly how real-time personalization will work inside Hyp.
The 'obvious' version of how it should work is easy. An AI agent looks at this user, on this page, in this moment, pulls up all their data, and decides what to show them.
Unfortunately that's not really practical or possible.
Running an LLM query for every page load of your website is madness. Even running an LLM query for each user every hour, even if you only look at active users, is also madness. I've done this in a prototype and it works perfectly. Real e-commerce businesses have millions of users though, and that naive approach won't scale.
The trick is where to apply the AI agents intelligently. This is a problem I believe all CRM and marketing automation vendors are wrestling with right now, and why no clear winner has emerged. It takes time to figure out the architecture especially as 'agentic' wasn't even a thing 2 years ago.
The question therefore I've been considering this week is:
What's the smallest unit you can put an agent over and still have a customer experience it as personal?
If the marketer's time moves away from wiring up marketing automation flows, triggered campaigns, and weekly business-as-usual, batch-and-blast email campaigns, SOMETHING has to decide what each customer sees. And that something is the Decisioning Layer.
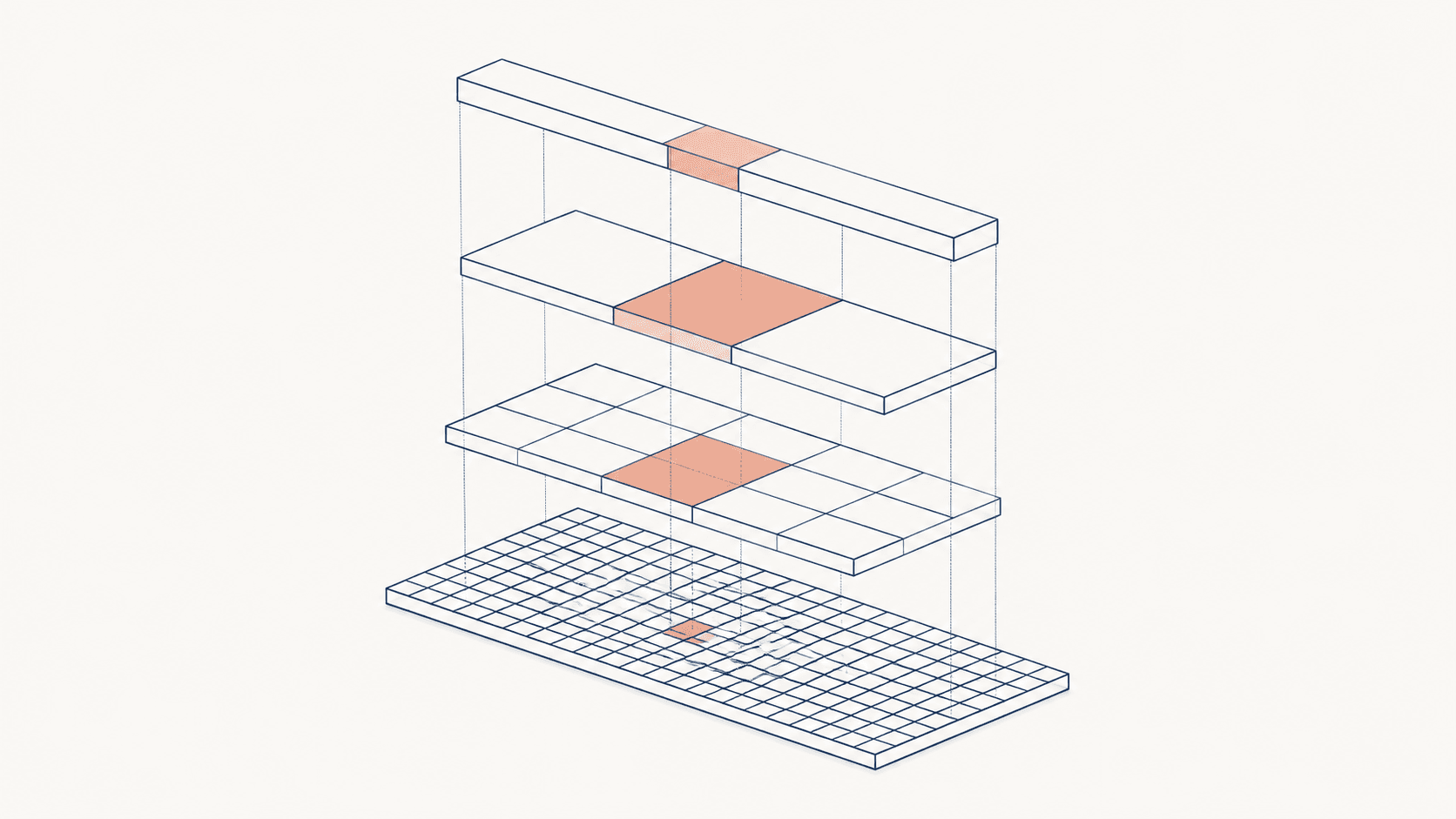
Due to the constraints I outlined above (not doing LLM generation for each user individually), my hypothesis is that the most practical atomic unit for personalisation will be a micro segment. Something with more granularity than RFM or 'has bought in the past 7 days', but not so granular that compute blows up when we run decisions hourly.
Currently at Hyp I'm segmenting on a number of axes (around 10). Some of those axes are relatively discrete, having around 5 values each. Some of them are way broader, and could have 100s of values. Multiplying all of those possible values together gets us to the order of tens or hundreds of thousands of micro-segments. Still a bit too large for computation.
However, not all of those segments will be active on the website or needing to be messaged. Excluding those I hope will get me into the low thousands for medium-sized ecommerce stores, mid thousands for the largest catalogues.
An example of such a segment might be:
- returning user who joined less than 60 days ago, purchased only once, has an affinity towards the North Face brand and has been actively researching jackets for the past 7 days, having added one to their basket. They are price sensitive (80% of their products in their first purchase were discounted and they used a discount code).
The Decisioning Layer that sits over these segments is complex. Machine learning, not Agents, do the cheapest selection work such as what creative to show, what offer, and what channel. Contextual bandits have been proven for this kind of task and are fast.
Agents sit on top, reasoning over the segment rather than the user. They have access to tools allowing them to query the underlying data for context (for example, have any new North Face products been added to the store's catalog recently? Are any out of stock jackets now back in stock? Are any jackets on sale? What does the return rate look like for people who ordered these items in the past?). If the agent finds useful context, that can supplement the output from the contextual bandits.
The frequency of how often this layer runs is most likely hourly (a good trade-off between performance and up-to-dateness). Remember, this isn't about speed of computing segments (that challenge has been solved). It's the speed of having agents work in conjunction with those segments that is the key architecture decision.
The output of this layer is written, precomputed, to medium-speed storage where it can be queried in seconds (example might be showing the marketer the decisions in their Hyp dashboard), or to the hot-path where it can be queried in <50ms (for on-site or in-app personalisation).
The thing I like about this approach is observability. The marketer can sample any one segment, read what the agent decided this hour, and form a view on whether what it decided was reasonable. The decisioning is auditable in a way that "real-time per-user inference" can't be, because there are only ever a few thousand decisions in flight and each one is attached to a description of who it's for.
This doesn't mean I'm giving up on 1-2-1 personalisation. Even though decisions are made at the micro-segment level, they can still include 'merge tag' placeholders - areas that can be filled in at runtime. Taking the example above, when the North Face banner is shown on the website, we could still insert the user's name, or any other data we know about them or what they've bought or looked at, into that banner.
Braze, Klaviyo, Iterable, Bloomreach are mostly acquiring smaller AI and data vendors and bolting them on top of triggered workflow engines. That's a real product shipping today and it works as a shortcut, but the underlying data schemas weren't built for agents and the workflow engine wasn't built to be replaced. You can graft AI onto a triggered-workflow product and it'll still want to behave like a triggered workflow.
Klaviyo's own 2026 trends piece describes "self-optimizing systems that plan, execute, and adjust campaigns across channels in real time", which is exactly the world I think CRM is moving into. The interesting question is who actually builds the per-segment decisioning layer that lets that be true, rather than who writes the trend piece.
Agentic personalization is often described in pitches as one agent per user, when the economics force it to be per-segment and the segment is where the interesting product work happens. (Those who say they run one agent per user are often using machine learning models, not LLMs).
Using an LLM to generate a unique marketing plan for each of your millions of customers just doesn't work economically today, and I don't think it has to. Real success will be had by those who can figure out the optimal way to combine machine learning techniques like contextual bandits WITH agents.